|
| Monkey says: "Knowing DFIR Rockstars has its privileges!" (Mari's picture courteousy of her Google+ Profile) |
This post aims to build upon Mari DeGrazia'ssqlparse Python script which harvests data from unallocated and free blocks in SQLite databases. It is also available as a Windows command line exe and/or a Windows GUI exe here.
Further details regarding her initial script can be found here. Mari's script has proven so useful that its referred to in the SANS585 Advanced Smartphone Forensics course and by at least 2 books on mobile forensics (Practical Mobile Forensics by Bommisetty, Tamma and Mahalik (2014) and Learning iOS Forensics by Epifani and Stirparo (2015)).
Mari's impressive DFIR research in a variety of areas has also lead her to attain her well deserved DFIR Rockstar status as attested to by her fellow DFIR Rockstar, Heather Mahalik.
That's a pretty impressive introduction eh? Mari - my promotions check is in the mail right? Right? ;)
OK, so whats Monkey got to do with it?
I was spinning my paws looking at deleted SMS from an Android (circa 4.1.2) LG-E425 phone (aka LG Optimus L3 E430) when I remembered Mari's script and thought of some minor modifications that would allow analysts to recover additional string data from re-purposed SQLite pages.
A commercial mobile forensics tool was reporting a different number of deleted SMS on consecutive reads via flasher box. Specifically, the parsing of read 1 was producing X deleted SMS while the parsing of read 2 was producing X-1 deleted SMS.
Admittedly, the flasher box was initiating a reboot after each acquisition - so any unused pages in the phone's memory could have been freed/reused, thus affecting the number of recoverable deleted SMS.
However, as Monkey actually gets paid to do this for a living (pinch me, I must be dreaming!), a closer inspection was carried out.
While the total number of deleted SMS varied by one, there were two deleted SMS in report 1 that weren't in report 2. Additionally, there was one deleted SMS in report 2 that wasn't in report 1.
So while the net difference was one less SMS, there was a bit more going on behind the scenes.
Fortunately, the commercial forensic tool also showed the image offset where these "deleted" SMS entries were found so we had a good starting point ...
OK Monkey, put your floaties on. It's time for some SQLite diving!
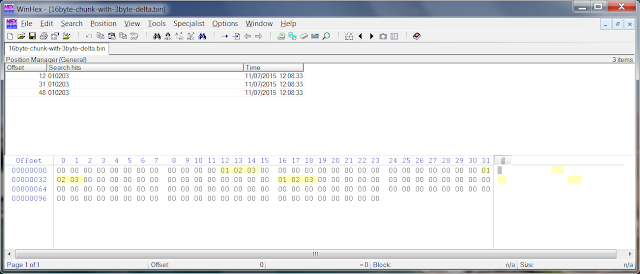
An SQLite database is comprised of a number of fixed sized pages. The number of pages and page size are declared in the file header. According to the official documentation, there are 4 types of page. The first byte of each page (occurring after the file header) tells us what type of page it is. The actual row data from a database table lives in a "Leaf Table B-Tree" page type. This has the flag value of 0xD (13 decimal). In the interests of readability / reducing carpal tunnel syndrome, we shall now refer to these pages as LTBT pages.
A typical LTBT page looks like this:
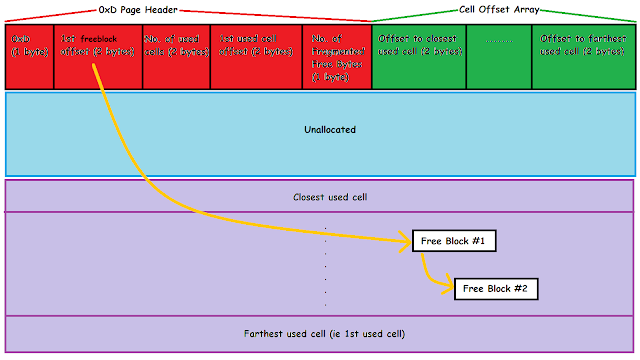 |
| An 0xD (LTBT) page with unallocated, allocated cells and free blocks |
Back to Monkey's problem (well, one he actually has a chance of solving!) ... I observed that some of those "deleted" SMS were appearing in non-LTBT pages. The commercial mobile forensic tool was then finding/listing some of these entries but not all of them.
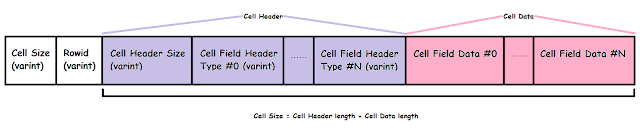
To accurately carve an entire SQLite record, you need to know the record's schema (order and type of column data) before reading the actual data. Any pages with overwritten cell headers (eg repurposed pages) may be difficult to accurately carve for all records. However, if we narrow our record recovery to any string content within a page, it becomes a lot easier. See this previous blog post for further details on carving SQLite records.
Within our LG phone data, it appeared that a page previously employed as a LTBT page was then re-purposed as another type (flag = 5, an "Interior Table B-tree" page). However, as this new page only used the first (and last) few bytes of the page, it still had previous record data leftover in the Unallocated region (see picture below).
 |
| The Unallocated region in non-LTBT pages can contain previous record data! |
This previous data included some SMS records - some of which were being reported by the tool as deleted, while others were not.
This reporting discrepancy might have been because some of these SMS records also existed in allocated LTBT pages elsewhere or maybe it was due to the method the commercial tool was using to carve for SMS records. Due to the closed source nature of commercial tools, we can only speculate.
So rather than try to reverse engineer a proprietary tool, Monkey remembered Mari's sqlparse Python script and thought it might be easier/more beneficial to extend Mari's script to print the strings from all non-LTBT pages. By doing this, we can find which non-LTBT pages have previous row data in them (assuming the row data contained printable ASCII strings like SMS records). This will allow us to hunt for deleted records more efficiently (versus running strings over the whole file and having to figure out which strings are allocated / not allocated).
Bceause Mari had written her code in a logical / easy to understand manner (and commented it well!), it didn't take long to modify initially and only required about 10 extra lines of code.
You can download the updated software (command line Python, command line Windows exe, Windows GUI exe) from Mari's Github page. She is also writing an accompanying blog post which you can find at her blog here.
The Script
From my GitHub account, I "forked" (created my own copy of) Mari's SQLite-Deleted-Records-Parser project, made my changes and then committed it to my own branch. Then I submitted a "pull" request to Mari so she could then review and accept the changes. Mari then found a interoperability bug regarding the new code and the existing raw mode which she then also fixed. Thanks Mari!At the start of the script, I added code to parse the optional -p flag (which is stored as the "options.printpages" boolean) so the script knows when to print the non-LTBT page printable characters to the user specified output file.
Next, I added an "elif" (else if) to handle non-LTBT pages (ie pages where the flag does not equal 13). This is where I stuffed up as I did not allow for the user specifying -r for raw mode (dumps deleted binary data) at the same time as the -p option. Mari fixed it so that in raw + printpages mode, the printable strings are now dumped from non-LTBT pages and deleted content is dumped from LTBT pages (as before).
Here's our cross-bred "elif" code (as of version 1.3):
elif (options.printpages):
# read block into one big string, filter unprintables, then print
pagestring = f.read(pagesize-1) # we've already read the flag byte
printable_pagestring = remove_ascii_non_printable(pagestring)
if options.raw == True:
output.write("Non-Leaf-Table-Btree-Type_"+ str(flag) + ", Offset " + str(offset) + ", Length " + str(pagesize) + "\n")
output.write("Data: (ONLY PRINTABLE STRINGS ARE SHOWN HERE. FOR RAW DATA, CHECK FILE IN HEX VIEWER AT ABOVE LISTED OFFSET):\n\n")
output.write(printable_pagestring)
output.write( "\n\n")
else:
output.write("Non-Leaf-Table-Btree-Type_" + str(flag) + "\t" + str(offset) + "\t" + str(pagesize) + "\t" + printable_pagestring + "\n" )
The code above is called for each page.
Depending on if we are in raw mode, the output is written as binary (raw mode) or tab separated text (not raw mode) to the user specified output file.
Depending on the number of non-LTBT pages and their string content, the output file might be considerably larger if you run the script with the -p argument versus without the -p argument.
In both raw/not raw mode output files there are some common output field names.
The "Non-Leaf-Table-Btree-Type_Z" field shows what type of page is being output. Where Z is the flag type of the non-LTBT page (eg 2, 5, 10, 0 etc).
The offset field represents the file offset for that page (should be a multiple of the page size).
No prizes for guessing what the page size field represents (this should be constant).
The last field will be the actual printable text. Because its removing unprintable characters, the output string should not be too large, which should make it easier to spot any strings of interest.
Here's the help text:
cheeky@ubuntu:~$ python ./sqlparse.py -h
Usage: Parse deleted records from an SQLite file into a TSV File or text file
Examples:
-f /home/sanforensics/smsmms.db -o report.tsv
-f /home/sanforensics/smssms.db -r -o report.txt
Options:
-h, --help show this help message and exit
-f smsmms.db, --file=smsmms.db
sqlite database file
-o output.tsv, --output=output.tsv
Output to a tsv file. Strips white space, tabs and
non-printable characters from data field
-r, --raw Optional. Will out put data field in a raw format and
text file.
-p, --printpages Optional. Will print any printable non-whitespace
chars from all non-leaf b-tree pages (in case page has
been re-purposed). WARNING: May output a lot of string
data.
cheeky@ubuntu:~$
Testing
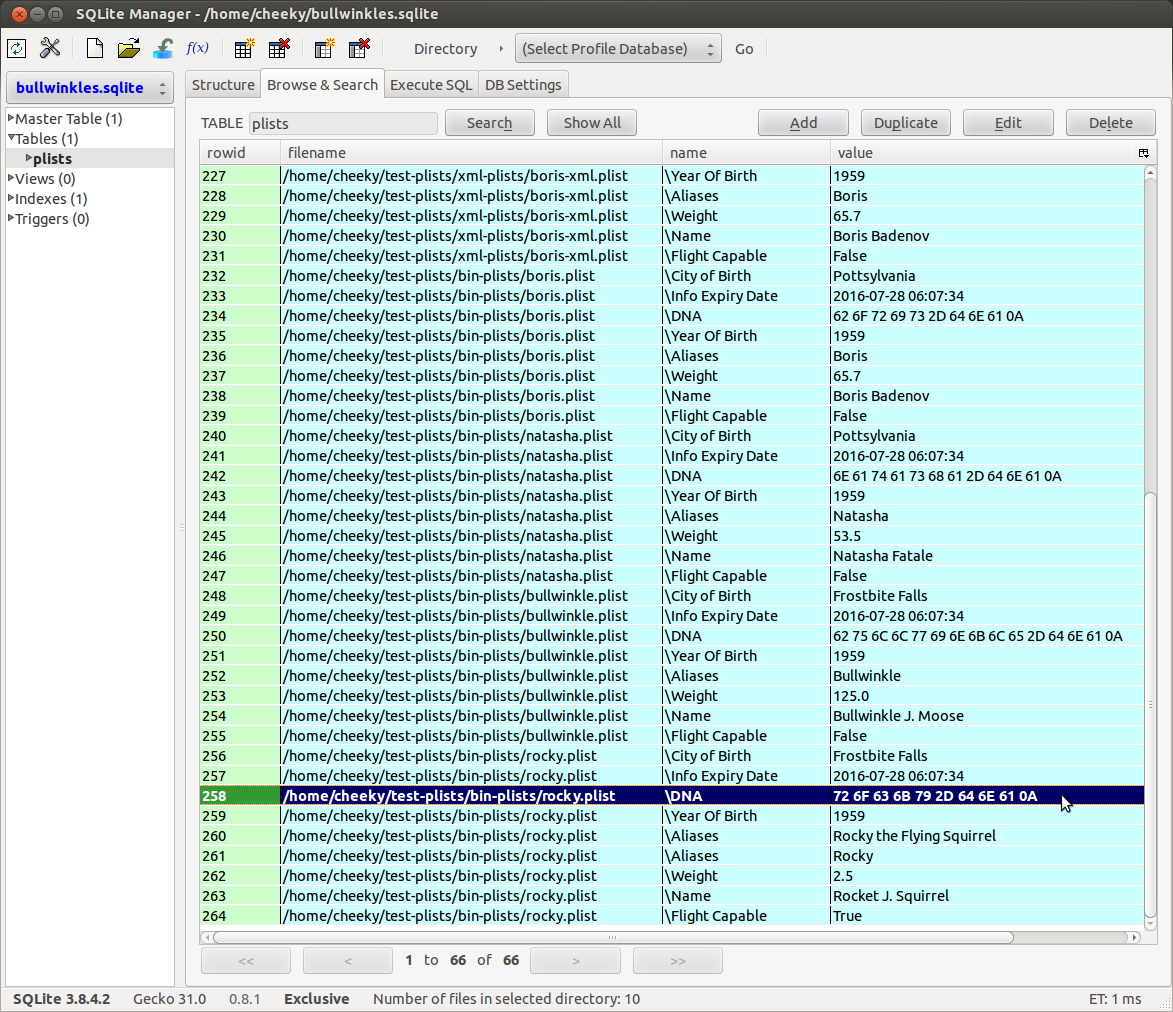
I tested the new script with an existing test Android mmssms.db and it seemed to work OK as I was able to see non-LTBT string content for various pages.To show you that new code doesn't fall in a screaming heap, on an Ubuntu 14.04 64-bit VM running Python 2.7, we're going to use the SQLite Manager Firefox plugin to create a test database (testsms.sqlite) with a test table (sms). Then we'll populate the table with some semi-amusing test data and then use a hex editor to manually add a test string ("OMG! Such WOW!!!") into a non-LTBT page (freelist page).
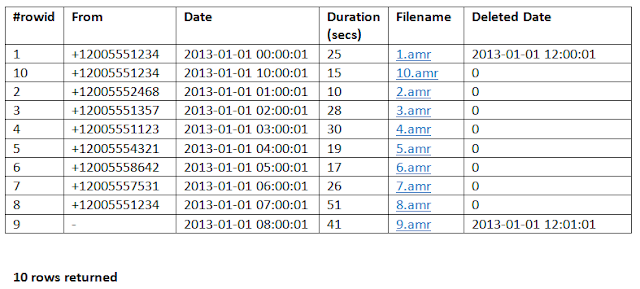
Here's the test "sms" table row data:
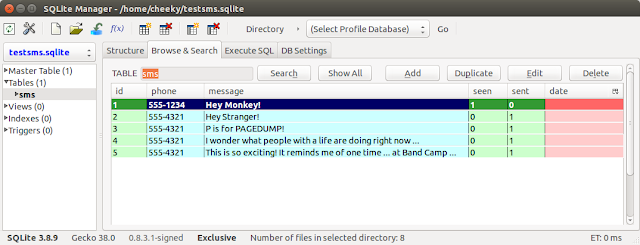 |
| One time ... at Band Camp ... |
Here's the relevant database header info screenshot:
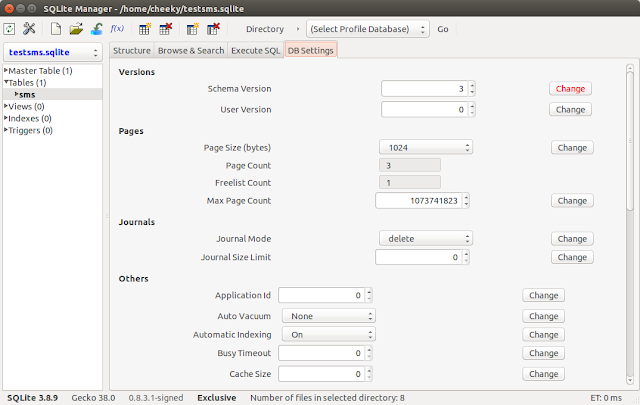 |
| Note: The page size is 1024 bytes and there are 3 total pages. The last page is on the freelist (unused). |
To create a non-LTBT page (page with a non 0xD flag value), I added another test table, added some rows and then dropped (deleted) that table. The database's auto-vacuum was not set. This resulted in the third page being created and then having its type flag set to 0 (along with any row data it seems). This suggests that pages on the free list have their first byte set to zero and it also may not be possible to recover strings from zeroed freelist pages. At any rate, we now have a non-LTBT page we can manually modify and then parse with our new code.
Here's the gory page by page breakdown of our testsms.sqlite file ...
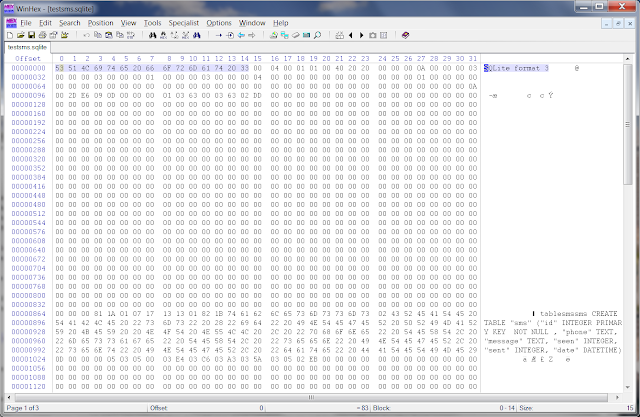 |
| Page 1 starts with the "SQLite format 3" string and not a flag type. |
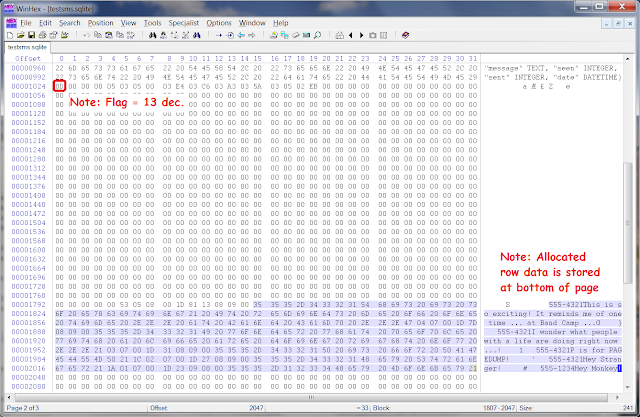 |
| Page 2 contains the test "sms" table data (ie LTBT page). |
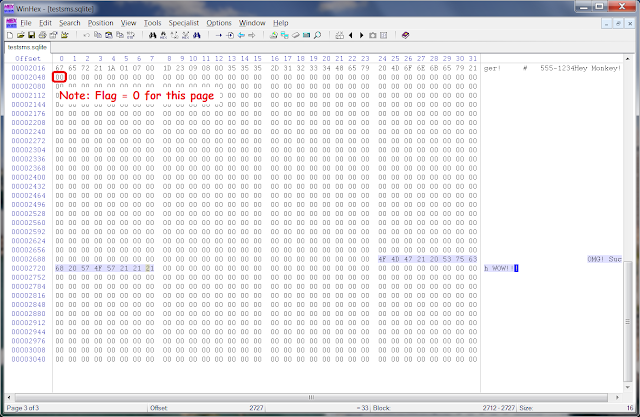 |
| Page 3 contains the freelist page (non-LTBT) and our test string. |
After using WinHex to add our test string to an arbitrary offset in the last page, we then ran our script (without the -p) and checked the contents of the outputfile.
cheeky@ubuntu:~$ python ./sqlparse.py -f testsms.sqlite -o testoutput.tsv
cheeky@ubuntu:~$
Here's what the testoutput.tsv file looked like:
 |
As expected, our test string in a non-LTBT page was not extracted.
Then we re-ran the script with the -p argument ...
cheeky@ubuntu:~$ python ./sqlparse.py -f testsms.sqlite -o testoutput.tsv -p
cheeky@ubuntu:~$
Here's the output file:
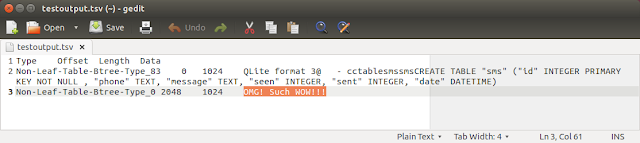 |
The new version of the script has successfully extracted string content from both of the non-LTBT pages (ie page 1 and page 3).
OMG! Such WOW!!! Indeed ...
You might have noticed the first entry (at offset 0) being "Non-Leaf-Table-Btree-Type_83". This is because the very first page in SQLite database starts with the string "SQLite format 3". There is no flag as such. "S" in ASCII is decimal 83 so thats why its declaring the type as 83. You can also see the rest of the string ("QLite format 3") following on with the rest of the printable string data in the Data column.
OK now we try adding the -r (raw) mode argument:
cheeky@ubuntu:~$ python ./sqlparse.py -f testsms.sqlite -o testoutput.tsv -p -r
cheeky@ubuntu:~$
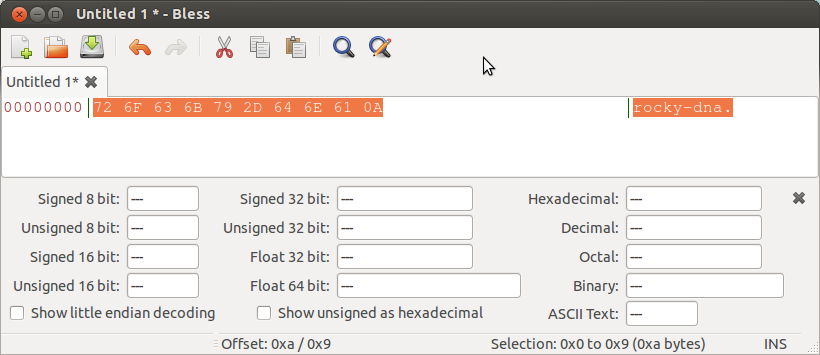
Because there's now binary content in the output file, Ubuntu's gedit spits the dummy when viewing it. So we use the Bless Hex editor to view the output file instead.
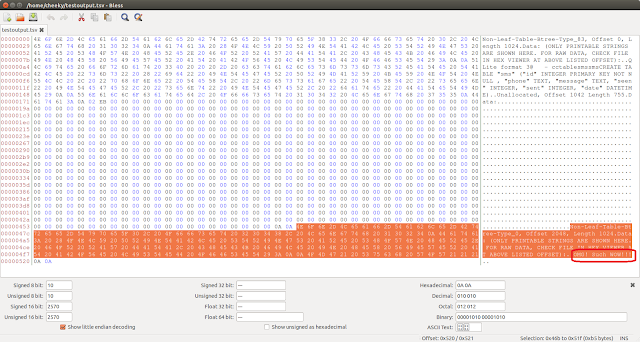 |
| Raw Mode + PrintPages Mode Output |
Notice how the first page's string content is shown (look for the "Qlite format 3" string towards to top of the pic). Remember, the first page is not considered an LTBT page, so its printable strings are retrieved.
There's also a bunch of Unallocated bytes retrieved (values set to zero) from offset 1042 which corresponds to Page 2's Unallocated area. Remember, Page 2 is an LTBT page - so the script only extracts the unallocated and free blocks (if present).
And finally, circled in red is our test string from Page 3 (a non-LTBT page type).
Cool! It looks like everything works!
Similarly, I re-ran the script on a Windows 7 Pro 64-bit PC running Python 2.7 with the same results.
Final Thoughts
Special Thanks again to Mari for releasing her sqlparse script and also for her prompt help and patience in rolling out the new updates.I contacted her on Thursday about the idea and just a few short days later we were (well, she was) already releasing this solution ... Awesome!
A lesson (re)learned was that even if you're only adding a few lines of code, be aware of how it fits into the existing code structure. None of this, "I'm not touching that part of the code, so it should be OK *crosses fingers*". Especially because it was someone else's baby, Monkey should have re-tested all of the existing functionality before requesting a merge. Thankfully in this case, the original author was available to quickly fix the problem and the solution was relatively straight forward.
During the initial investigation of the LG mmssms.db database, I checked the file header and there were no freelist (unused) pages allocated. The official documentation says:
A database file might contain one or more pages that are not in active use. Unused pages can come about, for example, when information is deleted from the database. Unused pages are stored on the freelist and are reused when additional pages are required.
The lack of freelist pages might have been because of the vacuum settings.
Anyhoo, with the -p option enabled, this new version of the script will process freelist pages and print any strings from there too (just in case).
Also, don't forget to check for rollback journal files (have "-journal" appended to DB filename) and write-ahead logs (have "-wal" appended to DB filename) as other potential sources of row data. They should be small enough to quickly browse with a hex editor. When using an SQLite reader to read a database file, be careful not to open it with those journal/log files in the same directory as that could result in the addition/removal of table data.
Be wary of the difference between documentation and implementation (eg the official SQLite documentation didn't mention pages with flag values of zero). Reading the available documentation is just one facet of research. Simulating / seeing real-world data is another. Reading the available source code is yet another. But for practical analysis, nothing beats having real-world data to compare/analyze.
After all, it was real-world data (and some well-timed curiosity) that lead us to adding this new functionality.
In keeping with the Rockstar theme ... Monkey, OUT! (drops microphone)