 |
| With some substantial assistance from Boss Rob ... Enter the Chunky Monkey! |
This post is targeted at those particularly interested in Python programming. If you are looking for a forensic wonder-tool post, you could be bitterly disappointed (yet again!).
Special Thanks to Rob (my boss and Hex Ninja Sensei) for kindly sharing his work which was the basis for this post.
After experiencing a few reversing/carving jobs, it seems that there's common theme.
Usually, the analyst wants to search a file for a given set of values (eg magic hex number) and then process the surrounding data accordingly. Complicating matters is that as storage media grow in size (especially in mobile devices), it is not always possible or timely to read the whole contents of a file into memory for searching. While Python does allow you to read files line by line, this is not really conducive to searching for (long) strings that cross line boundaries.
Rockin' Rob's method for handling these large files is to break them up into chunks but read slightly more than a chunk size (ie chunk size + delta). This way if a hit starts at the end of one chunk and crosses the chunk boundary, we can still find it/log it for later.
Note: The delta must be at least the same size as the largest record that is being searched for. Worst case scenario, the very last byte of the chunk contains the first byte of the search term - which means making delta as big as the largest record.
OK, first we are going to look at a theoretical chunky situation, then we will look at developing a utility (chunkymonkey.py) that can help us select one of two search algorithms and also help us to optimize our chunk size. Finally, we will implement our newly selected search algorithm and chunk size in an existing Windows Phone 8 script (wp8-sms.py) and compare it with the previous un-chunkified version. You can grab the chunkymonkey.py script (and the updated wp8-sms.py script) from my GitHub page.
Hehe, "Chunkymonkey" - That's gotta be one of my all time favourite tool names :)
So now let's take a look at a chunky example:
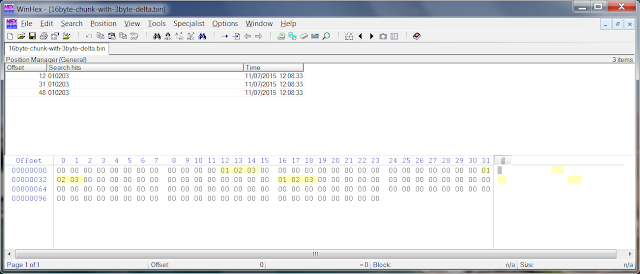 |
| 16 Byte Chunky Example |
Here we have a file which is divided into theoretical 16 byte chunks plus some extra bytes. The search term we are after is the three bytes 0x010203. They occur three times - once entirely before a chunk boundary at offset 12, once where it overlaps a chunk boundary at offset 31 and once right at the start of a chunk boundary at offset 48.
These three conditions simulate the possible chunk boundary situations. Our new chunkymonkey.py script will read a file chunk by chunk and if the search term starts before the end of a chunk boundary, it will log the file offset for later processing. If the search hit appears after the chunk boundary we ignore it. If the search hit starts after the chunk boundary but within chunk size+delta, we also ignore it as the next round of chunk processing should also pick it up.
We are also going to evaluate a couple of different search methods to see if we can speed our chunk searches up. The first one "all_indices" relies on the string.find method for finding substrings (think of the contents of a file as one big hex string). This was *ahem*"re-used"*ahem* from a recipe listed on code.activestate.com. The second method uses a compiled regular expression pattern. For more on Python regular expressions, you can read the documentation HOWTO.
Here's the code for each:
# Find all indices of a substring in a given string (using string.find)For benchmarking purposes, we are going to call these two functions from sliceNsearch (for "all_indices") and sliceNsearchRE (for "regsearch").
# From http://code.activestate.com/recipes/499314-find-all-indices-of-a-substring-in-a-given-string/
def all_indices(bigstring, substring, listindex=[], offset=0):
i = bigstring.find(substring, offset)
while i >= 0:
listindex.append(i)
i = bigstring.find(substring, i + 1)
return listindex
# Find all indices of the "pattern" regular expression in a given string (using regex)
# Where pattern is a compiled Python re pattern object (ie the output of "re.compile")
def regsearch(bigstring, pattern, listindex=[]):
hitsit = pattern.finditer(bigstring)
for it in hitsit:
# iterators only last for one shot so we capture the offsets to a list
listindex.append(it.start())
return listindex
These slice functions are going to read the specified file chunk by chunk and then call their respective search function. If the file size is less than one chunk size, the entire file will be read and searched in one go.
Once the search function returns a list of hit offsets (relative to the current chunk), these offsets will be converted to the equivalent file offsets for later processing.
For comparison, our new script will then also do a full file.read (ie no chunks) and process the resultant file string using the "all_indices" and "regsearch" functions. These wholeread functions can take a while to run so we can comment out those calls (to "wholereadRE" and "wholeread") later.
The goal is to compare the times taken when searching for hits in chunks Vs searching for hits via full file reads.
The secondary aim is to figure out which search function is quicker ie "regsearch" or "all_indices".
Here's the help text for chunkymonkey.py:
c:\Python27\python.exe chunkymonkey.py -hNow we'll call our new script (chunkymonkey.py) with our 16 byte chunk boundary hex file pictured earlier:
Running chunkymonkey.py v2015-07-10
usage: chunkymonkey.py [-h] inputfile term chunksize delta
Helps find optimal chunk sizes when searching large binary files for a known hex string
positional arguments:
inputfile File to be searched
term Hex Search string eg 53004d00
chunksize Size of each chunk (in decimal bytes)
delta Size of the extra read buffer (in decimal bytes)
optional arguments:
-h, --help show this help message and exit
c:\Python27\python.exe chunkymonkey.py 16byte-chunk-with-3byte-delta.bin 010203 16 3
Running chunkymonkey.py v2015-07-10
Search term is: 010203
Chunky sliceNsearch hits = 3, Chunky sliceNsearchRE hits = 3
Wholeread all_indices hits = 3, Wholeread regsearch hits = 3
Both the sliceNsearch and sliceNsearchRE chunky functions found the same hit offsets. To save space, I have commented out the part which prints each hit offset but rest assured that all hits listed were the same.
The wholeread (one big file.read) function calls to the "all_indices" and "regsearch" functions also found the same hits.
This proves that our new chunky functions will find the same search hits as the file.read (wholeread) functions.
So now what?
Python has an inbuilt profiling module (cProfile) which provides timing information for each function call. By using this, we can see which search method and chunk size is the most time efficient.
However, as the example bin file is not very large, let's try finding the optimum search algorithm/chunk size for a 7 GB Windows Phone 8 image instead. The test system is a i7 3.4-3.9 GHz with 16 GB RAM and 256 GB SSD running Win7 Pro x64 and Python 2.7.6.
Note: For Python 2, there appears to be a size limitation on (chunksize + delta). It must be less than ~2147483647.
This is probably because a Python int is implemented via a C long which is limited to 2^32 bits (ie max range is +/-2147483647). See also here for further details. Python 3 apparently does not have this limitation. So that kinda limits us to 2 GB chunk sizes at this point :'(
OK so let's try running chunkymonkey.py with a 2000000000 byte (~2GB) chunk size and 1000 byte delta size. The search term is "53004d00530074006500780074000000" ie UTF-16LE for "SMStext"
c:\Python27\python.exe -m cProfile chunkymonkey.py 7GBtestbin.bin 53004d00530074006500780074000000 2000000000 1000
Running chunkymonkey.py v2015-07-10
Search term is: 53004d00530074006500780074000000
Chunky sliceNsearch hits = 21, Chunky sliceNsearchRE hits = 21
Wholeread all_indices hits = 21, Wholeread regsearch hits = 21
2278 function calls (2217 primitive calls) in 198.065 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 argparse.py:1023(_SubParsersAction)
1 0.000 0.000 0.000 0.000 argparse.py:1025(_ChoicesPseudoAction)
1 0.000 0.000 0.000 0.000 argparse.py:1100(FileType)
1 0.000 0.000 0.000 0.000 argparse.py:112(_AttributeHolder)
1 0.000 0.000 0.000 0.000 argparse.py:1144(Namespace)
1 0.000 0.000 0.000 0.000 argparse.py:1151(__init__)
1 0.000 0.000 0.000 0.000 argparse.py:1167(_ActionsContainer)
3 0.000 0.000 0.000 0.000 argparse.py:1169(__init__)
34 0.000 0.000 0.000 0.000 argparse.py:1221(register)
14 0.000 0.000 0.000 0.000 argparse.py:1225(_registry_get)
5 0.000 0.000 0.000 0.000 argparse.py:1250(add_argument)
2 0.000 0.000 0.000 0.000 argparse.py:1297(add_argument_group)
5 0.000 0.000 0.000 0.000 argparse.py:1307(_add_action)
4 0.000 0.000 0.000 0.000 argparse.py:1371(_get_positional_kwargs)
1 0.000 0.000 0.000 0.000 argparse.py:1387(_get_optional_kwargs)
5 0.000 0.000 0.000 0.000 argparse.py:1422(_pop_action_class)
3 0.000 0.000 0.000 0.000 argparse.py:1426(_get_handler)
5 0.000 0.000 0.000 0.000 argparse.py:1435(_check_conflict)
1 0.000 0.000 0.000 0.000 argparse.py:147(HelpFormatter)
1 0.000 0.000 0.000 0.000 argparse.py:1471(_ArgumentGroup)
2 0.000 0.000 0.000 0.000 argparse.py:1473(__init__)
5 0.000 0.000 0.000 0.000 argparse.py:1495(_add_action)
1 0.000 0.000 0.000 0.000 argparse.py:1505(_MutuallyExclusiveGroup)
1 0.000 0.000 0.000 0.000 argparse.py:1525(ArgumentParser)
5 0.000 0.000 0.000 0.000 argparse.py:154(__init__)
1 0.000 0.000 0.001 0.001 argparse.py:1543(__init__)
2 0.000 0.000 0.000 0.000 argparse.py:1589(identity)
5 0.000 0.000 0.000 0.000 argparse.py:1667(_add_action)
1 0.000 0.000 0.000 0.000 argparse.py:1679(_get_positional_actions)
1 0.000 0.000 0.000 0.000 argparse.py:1687(parse_args)
1 0.000 0.000 0.000 0.000 argparse.py:1694(parse_known_args)
1 0.000 0.000 0.000 0.000 argparse.py:1729(_parse_known_args)
4 0.000 0.000 0.000 0.000 argparse.py:1776(take_action)
1 0.000 0.000 0.000 0.000 argparse.py:1874(consume_positionals)
1 0.000 0.000 0.000 0.000 argparse.py:195(_Section)
5 0.000 0.000 0.000 0.000 argparse.py:197(__init__)
1 0.000 0.000 0.000 0.000 argparse.py:2026(_match_arguments_partial)
4 0.000 0.000 0.000 0.000 argparse.py:2042(_parse_optional)
4 0.000 0.000 0.000 0.000 argparse.py:2143(_get_nargs_pattern)
4 0.000 0.000 0.000 0.000 argparse.py:2187(_get_values)
4 0.000 0.000 0.000 0.000 argparse.py:2239(_get_value)
4 0.000 0.000 0.000 0.000 argparse.py:2264(_check_value)
5 0.000 0.000 0.000 0.000 argparse.py:2313(_get_formatter)
5 0.000 0.000 0.000 0.000 argparse.py:555(_metavar_formatter)
5 0.000 0.000 0.000 0.000 argparse.py:564(format)
5 0.000 0.000 0.000 0.000 argparse.py:571(_format_args)
1 0.001 0.001 0.002 0.002 argparse.py:62(<module>)
1 0.000 0.000 0.000 0.000 argparse.py:627(RawDescriptionHelpFormatter)
1 0.000 0.000 0.000 0.000 argparse.py:638(RawTextHelpFormatter)
1 0.000 0.000 0.000 0.000 argparse.py:649(ArgumentDefaultsHelpFormatter)
1 0.000 0.000 0.000 0.000 argparse.py:683(ArgumentError)
1 0.000 0.000 0.000 0.000 argparse.py:703(ArgumentTypeError)
1 0.000 0.000 0.000 0.000 argparse.py:712(Action)
5 0.000 0.000 0.000 0.000 argparse.py:763(__init__)
1 0.000 0.000 0.000 0.000 argparse.py:803(_StoreAction)
4 0.000 0.000 0.000 0.000 argparse.py:805(__init__)
4 0.000 0.000 0.000 0.000 argparse.py:834(__call__)
1 0.000 0.000 0.000 0.000 argparse.py:838(_StoreConstAction)
1 0.000 0.000 0.000 0.000 argparse.py:861(_StoreTrueAction)
1 0.000 0.000 0.000 0.000 argparse.py:878(_StoreFalseAction)
1 0.000 0.000 0.000 0.000 argparse.py:895(_AppendAction)
1 0.000 0.000 0.000 0.000 argparse.py:932(_AppendConstAction
)
14 0.000 0.000 0.000 0.000 argparse.py:95(_callable)
1 0.000 0.000 0.000 0.000 argparse.py:958(_CountAction)
1 0.000 0.000 0.000 0.000 argparse.py:979(_HelpAction)
1 0.000 0.000 0.000 0.000 argparse.py:981(__init__)
1 0.000 0.000 0.000 0.000 argparse.py:998(_VersionAction)
1 0.199 0.199 8.755 8.755 chunkymonkey.py:110(sliceNsearchRE)
1 0.006 0.006 84.892 84.892 chunkymonkey.py:160(wholeread)
1 0.009 0.009 81.861 81.861 chunkymonkey.py:175(wholereadRE)
1 1.079 1.079 198.065 198.065 chunkymonkey.py:32(<module>)
4 0.006 0.001 24.389 6.097 chunkymonkey.py:41(all_indices)
4 19.234 4.808 19.238 4.809 chunkymonkey.py:50(regsearch)
1 0.191 0.191 21.474 21.474 chunkymonkey.py:60(sliceNsearch)
1 0.001 0.001 0.001 0.001 collections.py:1(<module>)
1 0.000 0.000 0.000 0.000 collections.py:26(OrderedDict)
1 0.000 0.000 0.000 0.000 collections.py:387(Counter)
3 0.000 0.000 0.000 0.000 gettext.py:130(_expand_lang)
3 0.000 0.000 0.000 0.000 gettext.py:421(find)
3 0.000 0.000 0.000 0.000 gettext.py:461(translation)
3 0.000 0.000 0.000 0.000 gettext.py:527(dgettext)
3 0.000 0.000 0.000 0.000 gettext.py:565(gettext)
1 0.000 0.000 0.000 0.000 heapq.py:31(<module>)
1 0.000 0.000 0.000 0.000 keyword.py:11(<module>)
3 0.000 0.000 0.000 0.000 locale.py:347(normalize)
1 0.000 0.000 0.000 0.000 ntpath.py:122(splitdrive)
1 0.000 0.000 0.000 0.000 ntpath.py:164(split)
1 0.000 0.000 0.000 0.000 ntpath.py:196(basename)
5 0.000 0.000 0.000 0.000 os.py:422(__getitem__)
12 0.000 0.000 0.000 0.000 os.py:444(get)
1 0.000 0.000 0.000 0.000 re.py:134(match)
15 0.001 0.000 0.006 0.000 re.py:188(compile)
16 0.003 0.000 0.005 0.000 re.py:226(_compile)
4 0.000 0.000 0.000 0.000 sre_compile.py:178(_compile_charset)
4 0.000 0.000 0.000 0.000 sre_compile.py:207(_optimize_charset)
24/5 0.000 0.000 0.000 0.000 sre_compile.py:32(_compile)
13 0.000 0.000 0.000 0.000 sre_compile.py:354(_simple)
5 0.000 0.000 0.000 0.000 sre_compile.py:359(_compile_info)
10 0.000 0.000 0.000 0.000 sre_compile.py:472(isstring)
5 0.000 0.000 0.000 0.000 sre_compile.py:478(_code)
5 0.000 0.000 0.001 0.000 sre_compile.py:493(compile)
61 0.000 0.000 0.000 0.000 sre_parse.py:126(__len__)
4 0.000 0.000 0.000 0.000 sre_parse.py:128(__delitem__)
109 0.000 0.000 0.000 0.000 sre_parse.py:130(__getitem__)
13 0.000 0.000 0.000 0.000 sre_parse.py:134(__setitem__)
49 0.000 0.000 0.000 0.000 sre_parse.py:138(append)
37/18 0.000 0.000 0.000 0.000 sre_parse.py:140(getwidth)
5 0.000 0.000 0.000 0.000 sre_parse.py:178(__init__)
79 0.000 0.000 0.000 0.000 sre_parse.py:182(__next)
35 0.000 0.000 0.000 0.000 sre_parse.py:195(match)
69 0.000 0.000 0.000 0.000 sre_parse.py:201(get)
8 0.000 0.000 0.000 0.000 sre_parse.py:257(_escape)
9/5 0.000 0.000 0.000 0.000 sre_parse.py:301(_parse_sub)
10/6 0.000 0.000 0.000 0.000 sre_parse.py:379(_parse)
5 0.000 0.000 0.000 0.000 sre_parse.py:67(__init__)
5 0.000 0.000 0.001 0.000 sre_parse.py:675(parse)
4 0.000 0.000 0.000 0.000 sre_parse.py:72(opengroup)
4 0.000 0.000 0.000 0.000 sre_parse.py:83(closegroup)
24 0.000 0.000 0.000 0.000 sre_parse.py:90(__init__)
5 0.000 0.000 0.000 0.000 {_sre.compile}
1 0.000 0.000 0.000 0.000 {binascii.hexlify}
1 0.000 0.000 0.000 0.000 {binascii.unhexlify}
3 0.000 0.000 0.000 0.000 {getattr}
26 0.000 0.000 0.000 0.000 {hasattr}
133 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {iter}
342/327 0.000 0.000 0.000 0.000 {len}
2 0.000 0.000 0.000 0.000 {max}
8 0.000 0.000 0.000 0.000 {method 'add' of 'set' objects}
452 0.003 0.000 0.003 0.000 {method 'append' of 'list' objects}
4 0.002 0.001 0.002 0.001 {method 'close' of 'file' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
6 0.000 0.000 0.000 0.000 {method 'extend' of 'list' objects}
55 24.382 0.443 24.382 0.443 {method 'find' of 'str' objects}
4 0.003 0.001 0.003 0.001 {method 'finditer' of '_sre.SRE_Pattern' objects}
78 0.001 0.000 0.001 0.000 {method 'get' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'groups' of '_sre.SRE_Match' objects}
5 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
3 0.000 0.000 0.000 0.000 {method 'join' of 'str' objects}
1 0.000 0.000 0.000 0.000 {method 'lstrip' of 'str' objects}
3 0.000 0.000 0.000 0.000 {method 'match' of '_sre.SRE_Pattern' objects}
6 0.000 0.000 0.000 0.000 {method 'pop' of 'dict' objects}
8 152.931 19.116 152.931 19.116 {method 'read' of 'file' objects}
8 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
7 0.000 0.000 0.000 0.000 {method 'replace' of 'str' objects}
3 0.000 0.000 0.000 0.000 {method 'reverse' of 'list' objects}
6 0.000 0.000 0.000 0.000 {method 'seek' of 'file' objects}
40 0.000 0.000 0.000 0.000 {method 'setdefault' of 'dict' objects}
42 0.000 0.000 0.000 0.000 {method 'start' of '_sre.SRE_Match' objects}
3 0.000 0.000 0.000 0.000 {method 'translate' of 'str' objects}
17 0.000 0.000 0.000 0.000 {method 'upper' of 'str' objects}
50 0.000 0.000 0.000 0.000 {min}
2 0.001 0.000 0.001 0.000 {nt.stat}
4 0.010 0.003 0.010 0.003 {open}
31 0.000 0.000 0.000 0.000 {ord}
7 0.001 0.000 0.001 0.000 {range}
8 0.000 0.000 0.000 0.000 {setattr}
1 0.000 0.000 0.000 0.000 {zip}
That's a LOT of output eh? Don't worry, we're only interested in the respective lines which contain the sliceNsearch, sliceNsearchRE, wholeread and wholereadRE functions. We're also going to focus on the "cumtime" column. This is the cumulative time spent in the function (not what your twisted mind first thought eh?) and thats the figure (highlighted in red) that we will use to compare the various runs with different chunk sizes.
To save space, here's a table detailing the runs (rounded to nearest second):
 |
| Function processing times by chunksize |
Delta was consistently set at 1000 bytes. There was some variability of a few seconds for consecutive runs of the same command but the overall trends seemed pretty consistent.
From the results above, we can see that the best "cumtime" is for a chunksize of 2000000000 bytes and using the chunky sliceNsearchRE function (which calls the "regsearch" function for each chunk).
Also note how the wholeread times are much larger than either the sliceNsearch or sliceNsearchRE times.
I'm not sure why the wholeread and wholereadRE functions are not returning consistent times regardless of the chunksize. In fact, the wholeread function time seems to be trending downwards with smaller chunks. Might be related to the memory used/freed by the chunky functions then affecting the availability of memory for the wholeread functions called after ... ie smaller chunk sizes result in more free memory for the wholereads to subsequently use.
Anyhoo, that's all well and good but how much difference can it make to an actual script which also has to process the hits and not just find them?
We modified our previous Windows Phone 8 SMS script (wp-sms.py) to use 2000000000 byte chunks (with 1000 byte delta) and modified it to call the sliceNsearchRE function. We then captured the cProfile stats.
First, we ran the previous unchunkified version of wp-sms.py which yielded these times:
c:\Python27\python.exe -m cProfile wp8-sms-orig.py -f 7GBtestbin.bin -o 7GBtestop.tsv
Running wp8-sms.py v2014-10-05
Skipping hit at 0x2dace9b0 - cannot find next field after SMStext
Skipping hit at 0x2dad6000 - cannot find next field after SMStext
Skipping hit at 0x31611c30 - cannot find next field after SMStext
Skipping hit at 0x4ce99bc0 - cannot find next field after SMStext
Skipping hit at 0x4ce99c00 - cannot find next field after SMStext
Skipping hit at 0x4ce9bf7c - cannot find next field after SMStext
Skipping hit at 0x66947c30 - cannot find next field after SMStext
Skipping hit at 0x6694ebc0 - cannot find next field after SMStext
Skipping hit at 0x6694ec00 - cannot find next field after SMStext
String substitution(s) due to unrecognized/unprintable characters at 0xccf26379
Processed 21 SMStext hits
Finished writing out 12 TSV entries
21672 function calls in 72.233 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
2 0.000 0.000 0.001 0.000 __init__.py:49(normalize_encoding)
2 0.001 0.000 0.009 0.004 __init__.py:71(search_function)
1 0.000 0.000 0.000 0.000 ascii.py:13(Codec)
1 0.000 0.000 0.000 0.000 ascii.py:20(IncrementalEncoder)
1 0.000 0.000 0.000 0.000 ascii.py:24(IncrementalDecoder)
1 0.000 0.000 0.000 0.000 ascii.py:28(StreamWriter)
1 0.000 0.000 0.000 0.000 ascii.py:31(StreamReader)
1 0.000 0.000 0.000 0.000 ascii.py:34(StreamConverter)
1 0.000 0.000 0.000 0.000 ascii.py:41(getregentry)
1 0.001 0.001 0.001 0.001 ascii.py:8(<module>)
1 0.000 0.000 0.000 0.000 codecs.py:322(__init__)
1 0.000 0.000 0.000 0.000 codecs.py:395(__init__)
1288 0.005 0.000 0.009 0.000 codecs.py:424(read)
72 0.000 0.000 0.000 0.000 codecs.py:591(reset)
1 0.000 0.000 0.000 0.000 codecs.py:651(__init__)
1288 0.001 0.000 0.009 0.000 codecs.py:669(read)
72 0.001 0.000 0.001 0.000 codecs.py:702(seek)
106 0.001 0.000 0.001 0.000 codecs.py:708(__getattr__)
2 0.000 0.000 0.000 0.000 codecs.py:77(__new__)
1 0.000 0.000 0.002 0.002 codecs.py:841(open)
1 0.000 0.000 0.000 0.000 gettext.py:130(_expand_lang)
1 0.000 0.000 0.000 0.000 gettext.py:421(find)
1 0.000 0.000 0.000 0.000 gettext.py:461(translation)
1 0.000 0.000 0.000 0.000 gettext.py:527(dgettext)
1 0.000 0.000 0.000 0.000 gettext.py:565(gettext)
1 0.000 0.000 0.000 0.000 locale.py:347(normalize)
3 0.000 0.000 0.000 0.000 optparse.py:1007(add_option)
1 0.000 0.000 0.000 0.000 optparse.py:1190(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:1242(_create_option_list)
1 0.000 0.000 0.000 0.000 optparse.py:1247(_add_help_option)
1 0.000 0.000 0.000 0.000 optparse.py:1257(_populate_option_list)
1 0.000 0.000 0.000 0.000 optparse.py:1267(_init_parsing_state)
1 0.000 0.000 0.000 0.000 optparse.py:1276(set_usage)
1 0.000 0.000 0.000 0.000 optparse.py:1312(_get_all_options)
1 0.000 0.000 0.000 0.000 optparse.py:1318(get_default_values)
1 0.000 0.000 0.000 0.000 optparse.py:1361(_get_args)
1 0.000 0.000 0.000 0.000 optparse.py:1367(parse_args)
1 0.000 0.000 0.000 0.000 optparse.py:1406(check_values)
1 0.000 0.000 0.000 0.000 optparse.py:1419(_process_args)
2 0.000 0.000 0.000 0.000 optparse.py:1516(_process_short_opts)
1 0.000 0.000 0.000 0.000 optparse.py:200(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:224(set_parser)
1 0.000 0.000 0.000 0.000 optparse.py:365(__init__)
3 0.000 0.000 0.000 0.000 optparse.py:560(__init__)
3 0.000 0.000 0.000 0.000 optparse.py:579(_check_opt_strings)
3 0.000 0.000 0.000 0.000 optparse.py:588(_set_opt_strings)
3 0.000 0.000 0.000 0.000 optparse.py:609(_set_attrs)
3 0.000 0.000 0.000 0.000 optparse.py:629(_check_action)
3 0.000 0.000 0.000 0.000 optparse.py:635(_check_type)
3 0.000 0.000 0.000 0.000 optparse.py:665(_check_choice)
3 0.000 0.000 0.000 0.000 optparse.py:678(_check_dest)
3 0.000 0.000 0.000 0.000 optparse.py:693(_check_const)
3 0.000 0.000 0.000 0.000 optparse.py:699(_check_nargs)
3 0.000 0.000 0.000 0.000 optparse.py:708(_check_callback)
2 0.000 0.000 0.000 0.000 optparse.py:752(takes_value)
2 0.000 0.000 0.000 0.000 optparse.py:764(check_value)
2 0.000 0.000 0.000 0.000 optparse.py:771(convert_value)
2 0.000 0.000 0.000 0.000 optparse.py:778(process)
2 0.000 0.000 0.000 0.000 optparse.py:790(take_action)
3 0.000 0.000 0.000 0.000 optparse.py:832(isbasestring)
1 0.000 0.000 0.000 0.000 optparse.py:837(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:932(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:943(_create_option_mappings)
1 0.000 0.000 0.000 0.000 optparse.py:959(set_conflict_handler)
1 0.000 0.000 0.000 0.000 optparse.py:964(set_description)
3 0.000 0.000 0.000 0.000 optparse.py:980(_check_conflict)
1 0.000 0.000 0.000 0.000 os.py:422(__getitem__)
4 0.000 0.000 0.000 0.000 os.py:444(get)
1 0.000 0.000 0.000 0.000 utf_16_le.py:18(IncrementalEncoder)
1 0.000 0.000 0.000 0.000 utf_16_le.py:22(IncrementalDecoder)
1 0.000 0.000 0.000 0.000 utf_16_le.py:25(StreamWriter)
1 0.000 0.000 0.000 0.000 utf_16_le.py:28(StreamReader)
1 0.000 0.000 0.000 0.000 utf_16_le.py:33(getregentry)
1 0.000 0.000 0.000 0.000 utf_16_le.py:8(<module>)
1 0.027 0.027 72.233 72.233 wp8-sms-orig.py:101(<module>)
72 0.006 0.000 0.016 0.000 wp8-sms-orig.py:114(read_nullterm_unistring)
831 0.001 0.000 0.004 0.000 wp8-sms-orig.py:148(read_filetime)
2 0.005 0.002 25.324 12.662 wp8-sms-orig.py:174(all_indices)
21 0.000 0.000 0.003 0.000 wp8-sms-orig.py:184(find_flag)
12 0.001 0.000 0.004 0.000 wp8-sms-orig.py:200(find_timestamp)
33 0.000 0.000 0.000 0.000 wp8-sms-orig.py:218(goto_next_field)
12 0.000 0.000 0.000 0.000 wp8-sms-orig.py:489(<lambda>)
2 0.006 0.003 0.007 0.004 {__import__}
1 0.000 0.000 0.002 0.002 {_codecs.lookup}
2576 0.002 0.000 0.002 0.000 {_codecs.utf_16_le_decode}
1547 0.002 0.000 0.002 0.000 {_struct.unpack}
2 0.000 0.000 0.000 0.000 {built-in method __new__ of type object at 0x000000001E29D0F0}
38 0.004 0.000 0.004 0.000 {built-in method utcfromtimestamp}
3 0.000 0.000 0.000 0.000 {filter}
106 0.000 0.000 0.000 0.000 {getattr}
4 0.000 0.000 0.000 0.000 {hasattr}
22 0.000 0.000 0.000 0.000 {hex}
8 0.000 0.000 0.000 0.000 {isinstance}
3881 0.001 0.000 0.001 0.000 {len}
639 0.005 0.000 0.005 0.000 {method 'append' of 'list' objects}
3 0.000 0.000 0.000 0.000 {method 'close' of 'file' objects}
1 0.000 0.000 0.000 0.000 {method 'copy' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
634 25.314 0.040 25.314 0.040 {method 'find' of 'str' objects}
21 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
38 0.000 0.000 0.000 0.000 {method 'isoformat' of 'datetime.datetime' objects}
1 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
2 0.000 0.000 0.000 0.000 {method 'join' of 'str' objects}
35 0.000 0.000 0.000 0.000 {method 'keys' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'lower' of 'str' objects}
4 0.000 0.000 0.000 0.000 {method 'pop' of 'list' objects}
4124 46.839 0.011 46.839 0.011 {method 'read' of 'file' objects}
4 0.000 0.000 0.000 0.000 {method 'replace' of 'str' objects
}
1 0.000 0.000 0.000 0.000 {method 'reverse' of 'list' objects}
13 0.000 0.000 0.000 0.000 {method 'rstrip' of 'str' objects}
1646 0.003 0.000 0.003 0.000 {method 'seek' of 'file' objects}
2 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
1 0.000 0.000 0.000 0.000 {method 'startswith' of 'str' objects}
993 0.001 0.000 0.001 0.000 {method 'tell' of 'file' objects}
3 0.000 0.000 0.000 0.000 {method 'translate' of 'str' objects}
5 0.000 0.000 0.000 0.000 {method 'upper' of 'str' objects}
13 0.001 0.000 0.008 0.001 {method 'write' of 'file' objects}
3 0.004 0.001 0.004 0.001 {open}
46 0.000 0.000 0.000 0.000 {range}
40 0.000 0.000 0.000 0.000 {setattr}
1 0.001 0.001 0.001 0.001 {sorted}
1288 0.000 0.000 0.000 0.000 {unichr}
Note: The total time was 72 seconds. 47 seconds of which were spent in the file.read function.
And after chunkification, it ran a lot quicker!
c:\Python27\python.exe -m cProfile wp8-sms.py -f 7GBtestbin.bin -o 7GBtestop-chunk.tsv
Running wp8-sms.py v2015-07-10
Skipping hit at 0x2dace9b0 - cannot find next field after SMStext
Skipping hit at 0x2dad6000 - cannot find next field after SMStext
Skipping hit at 0x31611c30 - cannot find next field after SMStext
Skipping hit at 0x4ce99bc0 - cannot find next field after SMStext
Skipping hit at 0x4ce99c00 - cannot find next field after SMStext
Skipping hit at 0x4ce9bf7c - cannot find next field after SMStext
Skipping hit at 0x66947c30 - cannot find next field after SMStext
Skipping hit at 0x6694ebc0 - cannot find next field after SMStext
Skipping hit at 0x6694ec00 - cannot find next field after SMStext
String substitution(s) due to unrecognized/unprintable characters at 0xccf26379
Processed 21 SMStext hits
Finished writing out 12 TSV entries
22694 function calls in 18.047 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
2 0.000 0.000 0.000 0.000 __init__.py:49(normalize_encoding)
2 0.000 0.000 0.001 0.000 __init__.py:71(search_function)
1 0.000 0.000 0.000 0.000 ascii.py:13(Codec)
1 0.000 0.000 0.000 0.000 ascii.py:20(IncrementalEncoder)
1 0.000 0.000 0.000 0.000 ascii.py:24(IncrementalDecoder)
1 0.000 0.000 0.000 0.000 ascii.py:28(StreamWriter)
1 0.000 0.000 0.000 0.000 ascii.py:31(StreamReader)
1 0.000 0.000 0.000 0.000 ascii.py:34(StreamConverter)
1 0.000 0.000 0.000 0.000 ascii.py:41(getregentry)
1 0.000 0.000 0.000 0.000 ascii.py:8(<module>)
1 0.000 0.000 0.000 0.000 codecs.py:322(__init__)
1 0.000 0.000 0.000 0.000 codecs.py:395(__init__)
1288 0.004 0.000 0.007 0.000 codecs.py:424(read)
72 0.000 0.000 0.000 0.000 codecs.py:591(reset)
1 0.000 0.000 0.000 0.000 codecs.py:651(__init__)
1288 0.001 0.000 0.008 0.000 codecs.py:669(read)
72 0.000 0.000 0.000 0.000 codecs.py:702(seek)
106 0.000 0.000 0.000 0.000 codecs.py:708(__getattr__)
2 0.000 0.000 0.000 0.000 codecs.py:77(__new__)
1 0.000 0.000 0.000 0.000 codecs.py:841(open)
1 0.000 0.000 0.000 0.000 gettext.py:130(_expand_lang)
1 0.000 0.000 0.000 0.000 gettext.py:421(find)
1 0.000 0.000 0.000 0.000 gettext.py:461(translation)
1 0.000 0.000 0.000 0.000 gettext.py:527(dgettext)
1 0.000 0.000 0.000 0.000 gettext.py:565(gettext)
1 0.000 0.000 0.000 0.000 locale.py:347(normalize)
3 0.000 0.000 0.000 0.000 optparse.py:1007(add_option)
1 0.000 0.000 0.000 0.000 optparse.py:1190(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:1242(_create_option_list)
1 0.000 0.000 0.000 0.000 optparse.py:1247(_add_help_option)
1 0.000 0.000 0.000 0.000 optparse.py:1257(_populate_option_list)
1 0.000 0.000 0.000 0.000 optparse.py:1267(_init_parsing_state)
1 0.000 0.000 0.000 0.000 optparse.py:1276(set_usage)
1 0.000 0.000 0.000 0.000 optparse.py:1312(_get_all_options)
1 0.000 0.000 0.000 0.000 optparse.py:1318(get_default_values)
1 0.000 0.000 0.000 0.000 optparse.py:1361(_get_args)
1 0.000 0.000 0.000 0.000 optparse.py:1367(parse_args)
1 0.000 0.000 0.000 0.000 optparse.py:1406(check_values)
1 0.000 0.000 0.000 0.000 optparse.py:1419(_process_args)
2 0.000 0.000 0.000 0.000 optparse.py:1516(_process_short_opts)
1 0.000 0.000 0.000 0.000 optparse.py:200(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:224(set_parser)
1 0.000 0.000 0.000 0.000 optparse.py:365(__init__)
3 0.000 0.000 0.000 0.000 optparse.py:560(__init__)
3 0.000 0.000 0.000 0.000 optparse.py:579(_check_opt_strings)
3 0.000 0.000 0.000 0.000 optparse.py:588(_set_opt_strings)
3 0.000 0.000 0.000 0.000 optparse.py:609(_set_attrs)
3 0.000 0.000 0.000 0.000 optparse.py:629(_check_action)
3 0.000 0.000 0.000 0.000 optparse.py:635(_check_type)
3 0.000 0.000 0.000 0.000 optparse.py:665(_check_choice)
3 0.000 0.000 0.000 0.000 optparse.py:678(_check_dest)
3 0.000 0.000 0.000 0.000 optparse.py:693(_check_const)
3 0.000 0.000 0.000 0.000 optparse.py:699(_check_nargs)
3 0.000 0.000 0.000 0.000 optparse.py:708(_check_callback)
2 0.000 0.000 0.000 0.000 optparse.py:752(takes_value)
2 0.000 0.000 0.000 0.000 optparse.py:764(check_value)
2 0.000 0.000 0.000 0.000 optparse.py:771(convert_value)
2 0.000 0.000 0.000 0.000 optparse.py:778(process)
2 0.000 0.000 0.000 0.000 optparse.py:790(take_action)
3 0.000 0.000 0.000 0.000 optparse.py:832(isbasestring)
1 0.000 0.000 0.000 0.000 optparse.py:837(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:932(__init__)
1 0.000 0.000 0.000 0.000 optparse.py:943(_create_option_mappings)
1 0.000 0.000 0.000 0.000 optparse.py:959(set_conflict_handler)
1 0.000 0.000 0.000 0.000 optparse.py:964(set_description)
3 0.000 0.000 0.000 0.000 optparse.py:980(_check_conflict)
1 0.000 0.000 0.000 0.000 os.py:422(__getitem__)
4 0.000 0.000 0.000 0.000 os.py:444(get)
2 0.000 0.000 0.000 0.000 re.py:188(compile)
2 0.000 0.000 0.000 0.000 re.py:226(_compile)
2 0.000 0.000 0.000 0.000 sre_compile.py:32(_compile)
2 0.000 0.000 0.000 0.000 sre_compile.py:359(_compile_info)
4 0.000 0.000 0.000 0.000 sre_compile.py:472(isstring)
2 0.000 0.000 0.000 0.000 sre_compile.py:478(_code)
2 0.000 0.000 0.000 0.000 sre_compile.py:493(compile)
24 0.000 0.000 0.000 0.000 sre_parse.py:138(append)
2 0.000 0.000 0.000 0.000 sre_parse.py:140(getwidth)
2 0.000 0.000 0.000 0.000 sre_parse.py:178(__init__)
30 0.000 0.000 0.000 0.000 sre_parse.py:182(__next)
2 0.000 0.000 0.000 0.000 sre_parse.py:195(match)
28 0.000 0.000 0.000 0.000 sre_parse.py:201(get)
2 0.000 0.000 0.000 0.000 sre_parse.py:301(_parse_sub)
2 0.000 0.000 0.000 0.000 sre_parse.py:379(_parse)
2 0.000 0.000 0.000 0.000 sre_parse.py:67(__init__)
2 0.000 0.000 0.000 0.000 sre_parse.py:675(parse)
2 0.000 0.000 0.000 0.000 sre_parse.py:90(__init__)
1 0.000 0.000 0.000 0.000 utf_16_le.py:18(IncrementalEncoder)
1 0.000 0.000 0.000 0.000 utf_16_le.py:22(IncrementalDecoder)
1 0.000 0.000 0.000 0.000 utf_16_le.py:25(StreamWriter)
1 0.000 0.000 0.000 0.000 utf_16_le.py:28(StreamReader)
1 0.000 0.000 0.000 0.000 utf_16_le.py:33(getregentry)
1 0.000 0.000 0.000 0.000 utf_16_le.py:8(<module>)
1 0.238 0.238 18.047 18.047 wp8-sms.py:105(<module>)
72 0.002 0.000 0.010 0.000 wp8-sms.py:122(read_nullterm_unistring)
831 0.001 0.000 0.003 0.000 wp8-sms.py:156(read_filetime)
6 12.618 2.103 12.618 2.103 wp8-sms.py:192(regsearch)
21 0.000 0.000 0.000 0.000 wp8-sms.py:201(find_flag)
12 0.001 0.000 0.004 0.000 wp8-sms.py:217(find_timestamp)
33 0.000 0.000 0.000 0.000 wp8-sms.py:235(goto_next_field)
2 0.472 0.236 17.791 8.896 wp8-sms.py:247(sliceNsearchRE)
12 0.000 0.000 0.000 0.000 wp8-sms.py:548(<lambda>)
2 0.001 0.000 0.001 0.000 {__import__}
1 0.000 0.000 0.000 0.000 {_codecs.lookup}
2576 0.002 0.000 0.002 0.000 {_codecs.utf_16_le_decode}
2 0.000 0.000 0.000 0.000 {_sre.compile}
1547 0.000 0.000 0.000 0.000 {_struct.unpack}
2 0.000 0.000 0.000 0.000 {built-in method __new__ of type object at 0x000000001E29D0F0}
38 0.000 0.000 0.000 0.000 {built-in method utcfromtimestamp}
3 0.000 0.000 0.000 0.000 {filter}
106 0.000 0.000 0.000 0.000 {getattr}
4 0.000 0.000 0.000 0.000 {hasattr}
22 0.000 0.000 0.000 0.000 {hex}
14 0.000 0.000 0.000 0.000 {isinstance}
3977 0.000 0.000 0.000 0.000 {len}
1382 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
3 0.000 0.000 0.000 0.000 {method 'close' of 'file' objects}
1 0.000 0.000 0.000 0.000 {method 'copy' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
4 0.000 0.000 0.000 0.000 {method 'extend' of 'list' objects}
2 0.000 0.000 0.000 0.000 {method 'fileno' of 'file' objects}
3 0.000 0.000 0.000 0.000 {method 'find' of 'str' objects}
6 0.000 0.000 0.000 0.000 {method 'finditer' of '_sre.SRE_Pattern' objects}
23 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
38 0.000 0.000 0.000 0.000 {method 'isoformat' of 'datetime.datetime' objects}
3 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
2 0.000 0.000 0.000 0.000 {method 'join' of 'str' objects}
35 0.000 0.000 0.000 0.000 {method 'keys' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'lower' of 'str' objects}
4 0.000 0.000 0.000 0.000 {method 'pop' of 'list' objects}
4129 4.704 0.001 4.704 0.001 {method 'read' of 'file' objects}
4 0.000 0.000 0.000 0.000 {method 'replace' of 'str' objects}
1 0.000 0.000 0.000 0.000 {method 'reverse' of 'list' objects}
13 0.000 0.000 0.000 0.000 {method 'rstrip' of 'str' objects}
1652 0.001 0.000 0.001 0.000 {method 'seek' of 'file' objects}
2 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
629 0.000 0.000 0.000 0.000 {method 'start' of '_sre.SRE_Match' objects}
1 0.000 0.000 0.000 0.000 {method 'startswith' of 'str' objects}
993 0.001 0.000 0.001 0.000 {method 'tell' of 'file' objects}
3 0.000 0.000 0.000 0.000 {method 'translate' of 'str' objects}
5 0.000 0.000 0.000 0.000 {method 'upper' of 'str' objects}
13 0.000 0.000 0.000 0.000 {method 'write' of 'file' objects}
4 0.000 0.000 0.000 0.000 {min}
2 0.000 0.000 0.000 0.000 {nt.fstat}
3 0.000 0.000 0.000 0.000 {open}
24 0.000 0.000 0.000 0.000 {ord}
46 0.000 0.000 0.000 0.000 {range}
40 0.000 0.000 0.000 0.000 {setattr}
1 0.000 0.000 0.000 0.000 {sorted}
1288 0.000 0.000 0.000 0.000 {unichr}
Note: The output from both versions of the wp8-sms.py script were identical.
Exciting times! It only took 18 seconds - less than 1/3 of the previous version's time!
Possibly because of the small number of hits (21), most of the time was spent in sliceNsearchRE and not processing the hits.
Given the same input file and search/chunk parameters (ie ~2GB chunk with 1k delta), more time was spent in sliceNsearchRE for wp8-sms.py (18 s) than for the previous chunkymonkey.py time (9 s) because sliceNsearchRE is being called twice in wp8-sms.py and only once in chunkymonkey.py.
The revised wp8-sms.py script was also run on a single store.vol file (18 MB) and the output results matched the previous version's output. Both scripts processed almost 6000 SMS in ~7 s.
Final Thoughts
A new tool (chunkymonkey.py) was written to help determine the optimum chunk size and search algorithm for finding a hex string in large binary files. Due to Python 2 limitations, the maximum chunk size has to be less than 2147483647 minus the delta size.Code from the tool was re-used/applied to an existing Windows Phone 8 SMS script (wp8-sms.py) and significantly reduced the processing time.
Further reduction of processing time may be possible in the future by utilizing threads (a way of concurrently calling multiple functions) however, this could make some already hack-tacular code even more complicated.
Over the next few hours/days, I plan to update/chunkify other selected Windows Phone scripts (ie wp8-callhistory.py, wp8-contacts.py) so that they can also run quicker against whole .bin files. I won't bother creating a new post for that though as the principles are already outlined here.
UPDATE (12/7/15):Have now updated the "wp8-sms.py", "wp8-callhistory.py" and "wp8-contacts.py" scripts to read large files in chunks.
Updated code is now available from my Github page.
Thanks again to Boss Rob for sharing his work!
Now where's that sundae?!